NAC: Neural Action Codec for Vision-Language-Action Models
Abstract
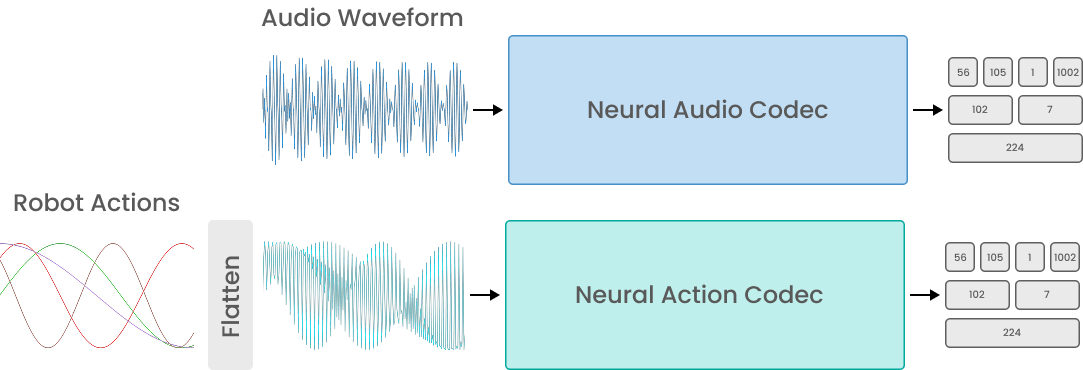
Vision-language-action (VLA) models rely on discrete action tokenizers to bridge continuous robot control and autoregressive sequence modeling, yet existing tokenizers often trade off between compression, latency, and downstream performance. We revisit this design through the lens of neural audio codecs—convolutional encoder–decoder architectures with residual vector quantization that serve as the standard front end for audio foundation models. Motivated by their success, we introduce the Neural Action Codec (NAC), which treats short robot action trajectories as multi-channel 1D signals and compresses them using a multi-scale RVQGAN architecture. We observe that audio-specific mel-spectrogram objectives are ill-suited for kinematic signals; however, by replacing them with simple time-domain and non-mel spectral reconstruction losses, audio-codec-style models can autoencode actions with high fidelity without substantial architectural changes. NAC provides a compact, ordered token space via offset codebooks, enabling standard autoregressive policies to operate over short, structured sequences. Meanwhile, a Vocos-style decoder with an ISTFT head and adversarial discriminators recovers smooth, detailed trajectories. Across LIBERO-10, RoboMimic, and a suite of real-world manipulation tasks, NAC achieves lower reconstruction error and higher success rates than binning, FAST, and prior VQ-based tokenizers at comparable or better compression rates. These results demonstrate that repurposed neural audio codecs offer a strong, practical backbone for learned action tokenization in modern VLAs.
Motivation: Actions as Signals
The action tokenizer is a critical design choice in VLA pretraining. Early methods relied on uniform per-dimension binning, producing prohibitively long token sequences for high-frequency control. Subsequent approaches like FAST used frequency-domain compression to shorten sequences. The primary difficulty lies in capturing the statistical regularities that let a policy model the underlying action distribution; a secondary challenge is latency, dictated by the compression rate and the tokenizer's decoding speed.
The audio generation domain has extensively studied and largely mitigated these same challenges. Audio and robotic actions share a continuous time-series structure but differ notably: action sequences operate at lower frequencies (\(30\text{–}60\,\text{Hz}\)) than audio (\(16\text{–}48\,\text{kHz}\)), and are multi-channel (typically 7–14 dimensions for robot joints or end-effectors). Despite these differences, the core objective of compressing continuous spatio-temporal signals remains fundamentally similar. Our key finding is that adapting audio codecs to actions primarily requires rethinking frequency-domain objectives: by removing mel-frequency losses, multi-scale RVQGAN models compress action sequences without major architectural changes.
Method: Neural Action Codec
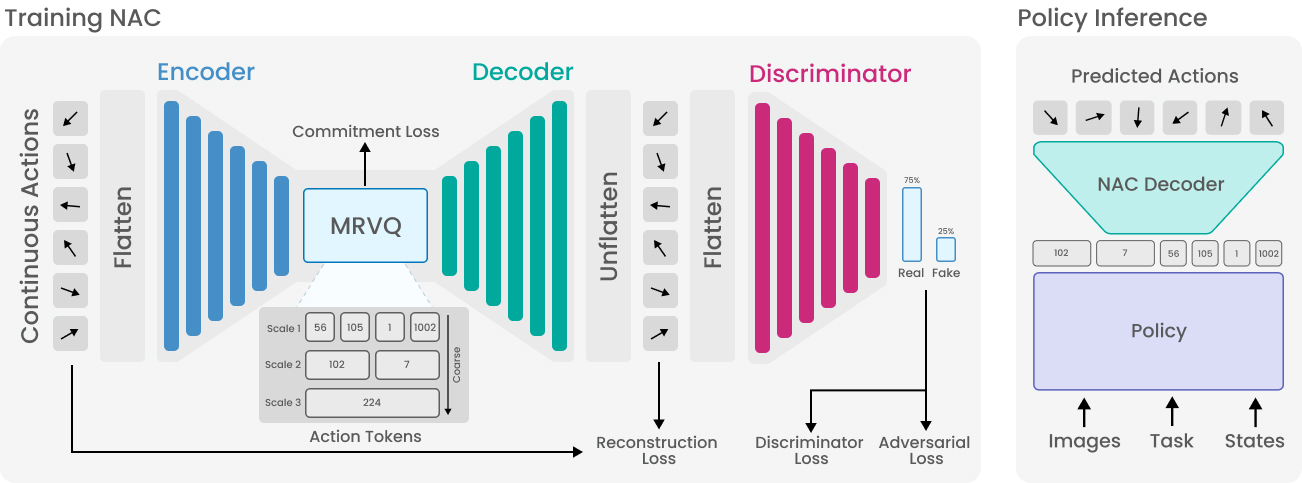
NAC maps continuous action chunks to 1D signals, compresses them via a convolutional encoder and multi-scale RVQ, and decodes them with a Vocoder-style decoder. We then train an autoregressive behavioral cloning policy that leverages NAC's structured token space.
Tokenizer
- 1D signal representation: The continuous action chunk is flattened along the temporal and feature dimensions into a single-channel pseudo-waveform of length \(L = H_a \cdot D_a\), where Ha is the action horizon and Da the action dimensionality.
- SEANet encoder: A fully convolutional encoder with strided downsampling, residual blocks, ELU activations, weight normalization, and reflection padding maps the waveform to a continuous latent \(z\).
- Multi-scale RVQ (MRVQ): Per-stage temporal pooling forces earlier stages to compress coarse, global trajectory structure over wide windows, while later stages capture fine-grained, high-frequency residuals. An aggressively scaled commitment loss (\(V_{\text{bins}}\) codebooks, λcommit = 10³) bounds the latent space and prevents codebook collapse.
- Decoder & ISTFT head: A Vocos-style backbone predicts STFT magnitude and phase; an inverse short-time Fourier transform reconstructs the 1D signal, with the ISTFT hop length synchronized to the encoder's hop length.
- Adversarial training: We adapt audio discriminators for 1D action signals; ablations show the DAC discriminator gives the strongest signal for robotic actions. Critically, we drop the mel-spectrogram loss entirely, using MSE, L1, or an unscaled spectrogram loss instead.
Behavioral Cloning Policy
We train an autoregressive policy on top of the frozen NAC tokenizer. To provide structured generation, NAC uses offset codebooks: with \(n_q\) scales, the policy vocabulary size is \(|\mathcal{V}| = n_q \times V_{\text{bins}} + 1\), accounting for a beginning-of-sequence token. All tokens for scale 0 are predicted first, followed sequentially by scale 1, and so forth. At inference, the policy generates tokens with this fixed layout, partitions them into per-scale segments, recovers code indices via modulo arithmetic, and decodes through the frozen detokenizer—executing the first few steps in a receding-horizon fashion.
Experiments
We compare NAC against continuous-control and discrete-token baselines—Bin, Diffusion Policy, FAST, VQ-VLA, and OAT—spanning naive binning, diffusion-based control, hand-designed compression, and learned tokenization. All policy comparisons share observation inputs, action horizons, and training protocols, differing only in action parameterization. We evaluate on LIBERO-10 and RoboMimic in simulation and a suite of real-world manipulation tasks.

Overall Manipulation Performance
NAC achieves the highest success rate on every benchmark. On LIBERO-10, it outperforms FAST by 11.71 points and OAT by 5.56 points, with similar gains on RoboMimic. In the real world, NAC reaches 50% total success versus 40% for both OAT and FAST, with the largest gains on tasks requiring precise, localized corrections such as grasping grapes and stacking blocks.
| Environment | Bin | Diffusion Policy | FAST | VQ-VLA | OAT | NAC (Ours) |
|---|---|---|---|---|---|---|
| LIBERO-10 | 3.95 ± 0.8 | 25.48 ± 1.3 | 38.02 ± 1.3 | 10.85 ± 1.85 | 44.17 ± 1.2 | 49.73 ± 1.0 |
| RoboMimic | 7.56 ± 1.05 | 27.25 ± 1.87 | 28.38 ± 2.37 | 21.44 ± 1.45 | 31.94 ± 2.15 | 33.94 ± 1.86 |
| Real World | 6.25 | 22.5 | 40.0 | 31.25 | 40.0 | 50.0 |
Can Audio Codecs Model Robot Actions?
Audio codecs are viable for action tokenization, provided audio-specific assumptions are removed. Mel-spectrogram training collapses downstream performance to nearly zero, while simple signal-domain or non-mel frequency objectives produce strong policies (MSE yields the strongest control; spectrogram loss the best reconstruction MSE). Removing the discriminator causes complete downstream failure, and replacing the ISTFT head with a linear decoder worsens both reconstruction and policy success.
| Recon. Loss | Perf. (%) | MSE |
|---|---|---|
| L1 | 44.78 ± 2.48 | 0.002 ± 0.005 |
| MSE | 49.2 ± 1.54 | 0.0008 ± 0.0007 |
| DCT | 47.85 ± 1.18 | 0.0007 ± 0.0008 |
| Mel Spec. | 0 ± 0.11 | 0.038 ± 0.026 |
| Spectrogram | 48.3 ± 2.92 | 0.0002 ± 0.001 |
| Discriminator | Perf. (%) | MSE |
|---|---|---|
| DAC | 49.45 ± 2.02 | 0.0005 ± 0.0018 |
| MPD | 46.28 ± 1.48 | 0.0005 ± 0.0007 |
| MRD | 45.68 ± 1.72 | 0.0004 ± 0.0006 |
| None | 0 | 0.35 ± 0.12 |
| Tokenizer Head | Perf. (%) | MSE |
|---|---|---|
| ISTFT | 48.3 ± 2.92 | 0.0002 ± 0.001 |
| Linear | 42.1 ± 1.54 | 0.0006 ± 0.001 |
Table 1: Action tokenization ablations on LIBERO-10. Performance (%) is downstream policy task success rate; MSE is reconstruction error on 14,000 validation action chunks.
Compression & Latency
NAC compresses each action chunk to 12 tokens, matching the best learned tokenizers while reducing token count by nearly 19× relative to Bin and 3× relative to FAST. Though slower than hand-designed tokenizers, NAC is significantly faster than VQ-VLA and operates within a practical range for real-time control.
| Method | Params (M) | Tokens | |K| | # of Bits | Enc (ms) | Dec (ms) | Recon (ms) |
|---|---|---|---|---|---|---|---|
| Bin | 0.002 | 224 | 1024 | 2240 | 0.045 | 0.039 | 0.079 |
| OAT | 65.207 | 12 | 1024 | 120 | 0.931 | 2.392 | 3.347 |
| VQ-VLA | 65.556 | 12 | 1024 | 120 | 7.086 | 4.045 | 11.049 |
| FAST | 0.000 | 36 | 1024 | 360 | 0.170 | 0.110 | 0.290 |
| NAC (Ours) | 63.006 | 12 | 1024 | 120 | 1.270 | 2.183 | 3.536 |
Reconstruction Quality
The video below compares the reconstruction fidelity of each tokenizer—how faithfully decoded trajectories track the ground-truth action signal across methods.
Real-World Manipulation
We evaluated all methods on 8 physical manipulation tasks spanning fine grasping, object placement, and deformable control, with 10 trials per task. NAC's compressed token space transfers effectively to physical control, outperforming alternatives on average.

| Task | Bin | Diffusion | FAST | VQ-VLA | OAT | NAC (Ours) |
|---|---|---|---|---|---|---|
| Weighing | 50 | 40 | 80 | 90 | 40 | 90 |
| Grapes | 0 | 30 | 80 | 30 | 80 | 100 |
| Marker | 0 | 30 | 60 | 30 | 50 | 50 |
| Two Blocks | 0 | 0 | 0 | 0 | 0 | 30 |
| Three Blocks | 0 | 0 | 0 | 0 | 10 | 0 |
| Chess | 0 | 0 | 10 | 0 | 40 | 10 |
| Place Stone | 0 | 0 | 10 | 50 | 30 | 40 |
| Fold Towel | 0 | 80 | 80 | 50 | 70 | 80 |
| Total | 6.25 | 22.5 | 40 | 31.25 | 40 | 50 |
The video below shows downstream policy rollouts, comparing closed-loop task execution across all tokenizers.
Citation
If you find this work useful, please consider citing our paper:
@misc{jawaid2026nac,
title={NAC: Neural Action Codec for Vision-Language-Action Models},
author={Ahad Jawaid and Yu Xiang},
year={2026},
institution={The University of Texas at Dallas}
}